API gateway & gRPC Generation
An API gateway is an API management tool that sits between a client and a multitude of backend services. It acts as the entrypoint for your system and serves as a reverse proxy that accepts all API calls and routes them to the correct backend service(s) to fulfill the request.
Because API gateways can be a very useful piece to any infrastructure, many software companies have emerged that sell it as their main product. These solutions provide certain niceties such as:
- UIs to discover APIs and view the full state of the gateway
- Analytics
- Metrics
- Automation workflows
- Security
- etc..
At Weave, we have gone a different route, as we usually do. We are fully generating our own gateway code! To serve it, we generate Traefik IngressRoute CRDs that route traffic to various backend services. And because all our gateway proxy code is auto-generated based on the protobuf definition of each API, all the authentication, rate-limiting, etc. happens after the API gateway has routed the request to the correct backend service; all without requiring our developers to write the same code over and over again. We take that toil away.
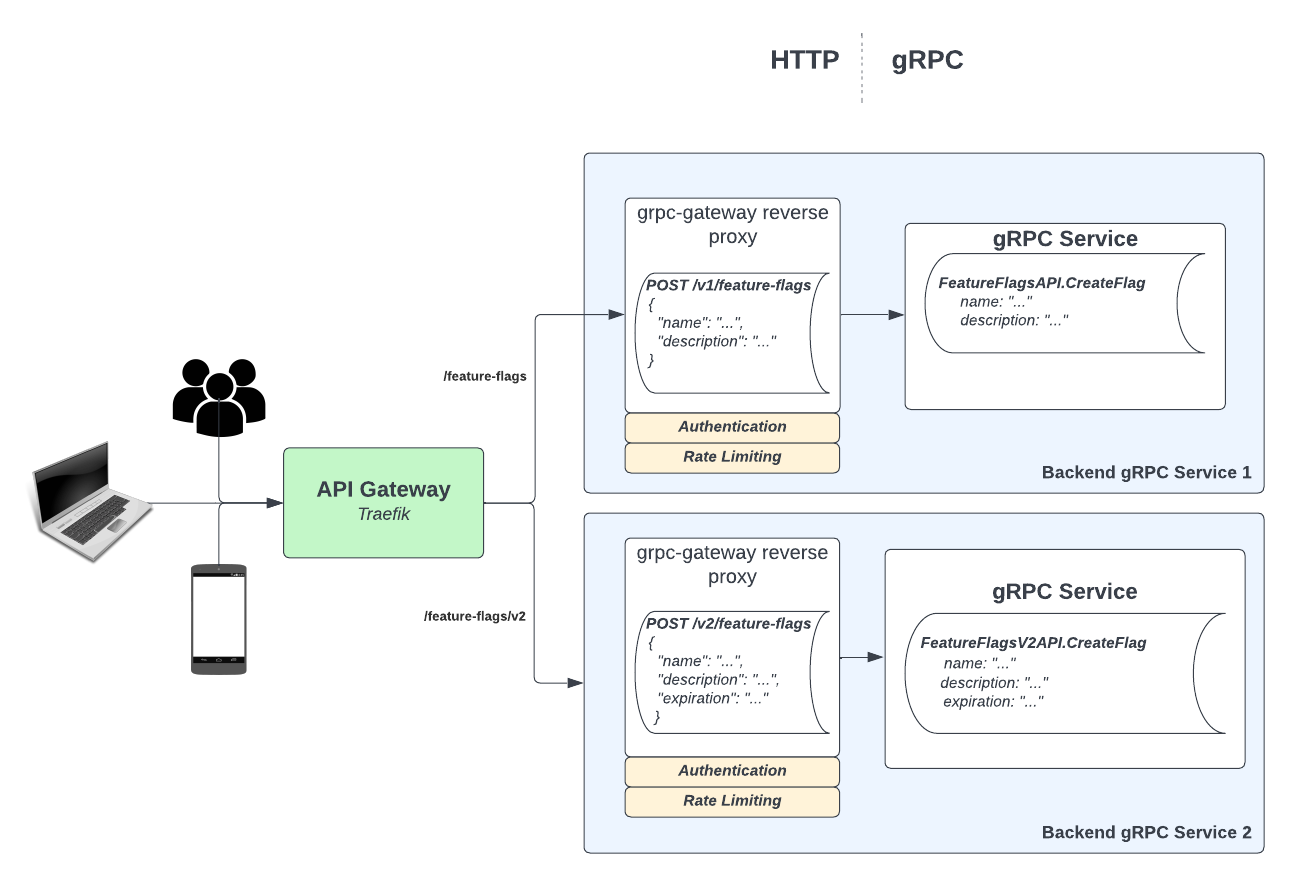
This post will walk through:
- Our protobuf generation pipeline
- How we prevent services from overriding another service’s route(s)
- Our custom protoc plugin
- What our generated gateway code looks like
- How everything fits together in this full system
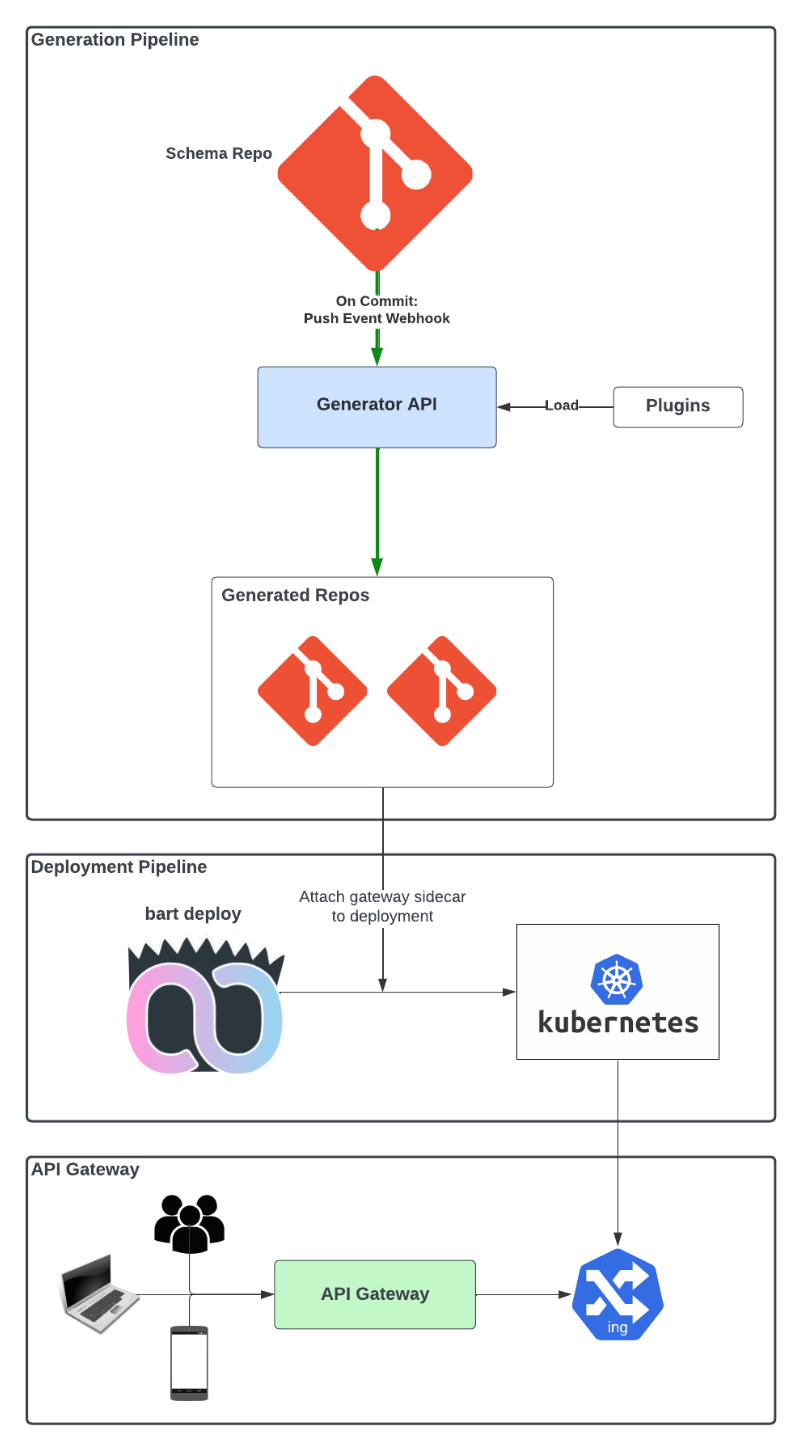
Generation Pipeline
schema Repository
Everything in our generation pipeline centers around our schema Git repository. All of our API contracts are expressed
in protobuf form and are stored in this repository, as shown above. We use buf, not only for our
proto generation, but to perform pull request checks such as:
- backwards compatibility
- linting
- ensure generation succeeds
This guarantees that a change to a particular “schema” cannot break backwards compatibility. It also ensures that all
schemas follow the same style guide that is outlined in the buf.yaml
file. This file, located in the root of the schema repository contains lint and breaking change detection rules, and a
list of dependencies.
As we were building out our API gateway, we realized that using Traefik IngressRoute CRDs could present the problem of
services stomping on each other’s routes. We ultimately made the choice that your route in the gateway was determined by
the location of your API in the schema repo, and thus, eliminating that risk. For example, the directory structure of
the schema repository roughly looks like this:
third-party # third-party proto files that have been copied over
weave
├── buf.yaml # buf configuration (linting, dependencies, etc.)
├── buf.gen.yaml # buf generation rules
├── shared # globally shared proto messages
└── schemas # ROOT OF API GATEWAY
└── feature-flags # v1
└── feature-flags.proto
└── v2
└── feature-flags.proto
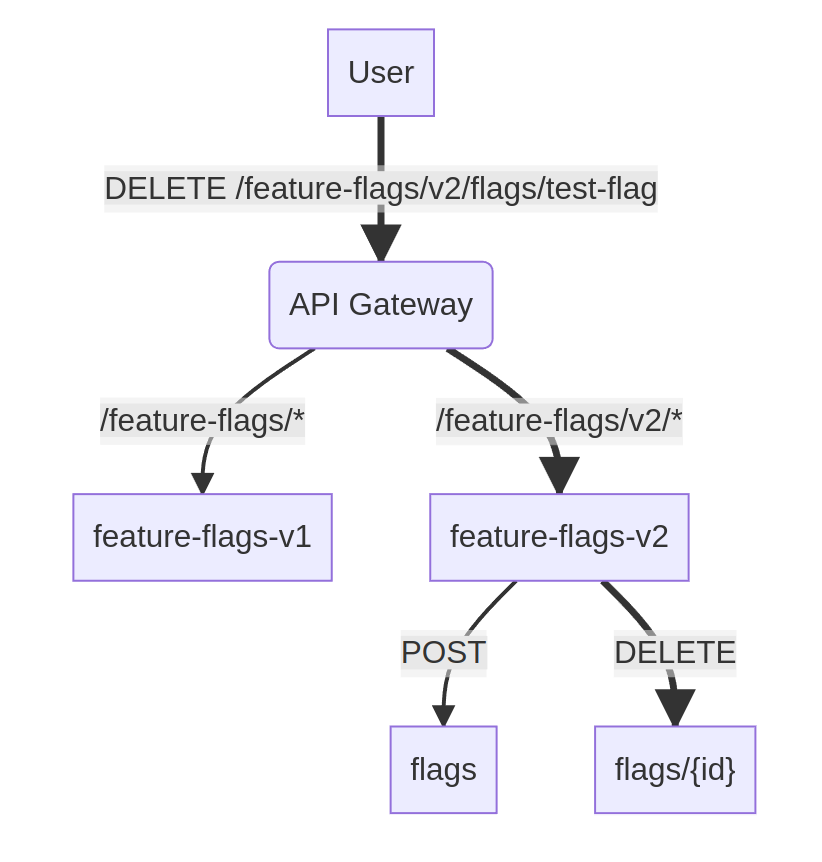
As you can see, we have a directory that is specifically for “schema” definitions, or APIs. The root of our API gateway
host starts at <schema-repo>/weave/schemas. That means, in the sample directory structure above, there would be a “v1”
feature-flags service accessible at https://<api-gateway-host>/feature-flags and a “v2” feature-flags service accessible
at https://<api-gateway-host>/feature-flags/v2.
<schema-repo>/weave/schemas/feature-flags -> https://<api-gateway-host>/feature-flags
<schema-repo>/weave/schemas/feature-flags/v2 -> https://<api-gateway-host>/feature-flags/v2
Consequently, all RPC methods defined in a particular proto definition are always relative to its path in the repo. For example, take the following trimmed-down version of the “v2” feature-flags service proto:
// source: schemas/feature-flags/v2
syntax = "proto3";
package featureflags.v2;
// FeatureFlagsServiceAPI is used for interacting with feature flags.
service FeatureFlagsServiceAPI {
// CreateFlag will create a new feature flag.
rpc CreateFlag(CreateFlagRequest) returns (Flag) {
option (google.api.http) = {
post: "/flags"
body: "flag"
};
}
// DeleteFlag will delete an existing feature flag and unset it on all associated users.
rpc DeleteFlag(DeleteFlagRequest) returns (google.protobuf.Empty) {
option (google.api.http) = {
delete: "/flags/{id}"
};
}
}
As outlined before, because the location of this “schema” is <schema-repo>/weave/schemas/feature-flags/v2, and because
the root of our API gateway lives at the path of <schema-repo>/weave/schemas, this service would be accessible through
the gateway at https://<api-gateway-host>/feature-flags/v2. But, because it defines two RPC methods with grpc-gateway
annotations, it would also have the following routes available:
POST https://<api-gateway-host>/feature-flags/v2/flags from:
rpc CreateFlag(CreateFlagRequest) returns (Flag) {
option (google.api.http) = {
post: "/flags"
body: "flag"
};
}
DELETE https://<api-gateway-host>/feature-flags/v2/flags/{id} from:
rpc DeleteFlag(DeleteFlagRequest) returns (google.protobuf.Empty) {
option (google.api.http) = {
delete: "/flags/{id}"
};
}
One thing to note is that just including an API in this repository does not mean you automatically get an ingress route created for you. The schema definition must include grpc-gateway annotations which tell the generator how to proxy each RPC endpoint from HTTP to gRPC. There are some services that choose to forego these annotations to keep their API private to the cluster.
The design decision of path-based routing rules has allowed us to implement this API gateway without any issues of routing, which is the most important part of an API gateway. Even with this implementation, there is still the possibility of a service squashing another service’s routing rules. That’s why we also have a deploy-time check that verifies the current service doesn’t violate any other service’s ingress routes.
The other piece that ensures unwanted changes aren’t committed is code ownership. When one of our teams adds a new API
to the schema repository, they also add their team as the code owner of that particular directory. This ensures that
another API can’t stomp on their routing or create a subdirectory that overrides on any routes defined in their primary
API.
Schema Generator API
The service that performs the actual generation of code is actually pretty simple. When a commit is made to any
branch in the schema repo, a GitHub webhook push event is sent to our schema-generator-api service which does a few
things:
- Runs proto generation
- Updates our schema metadata datastore
- Pushes generated content to our generated repositories
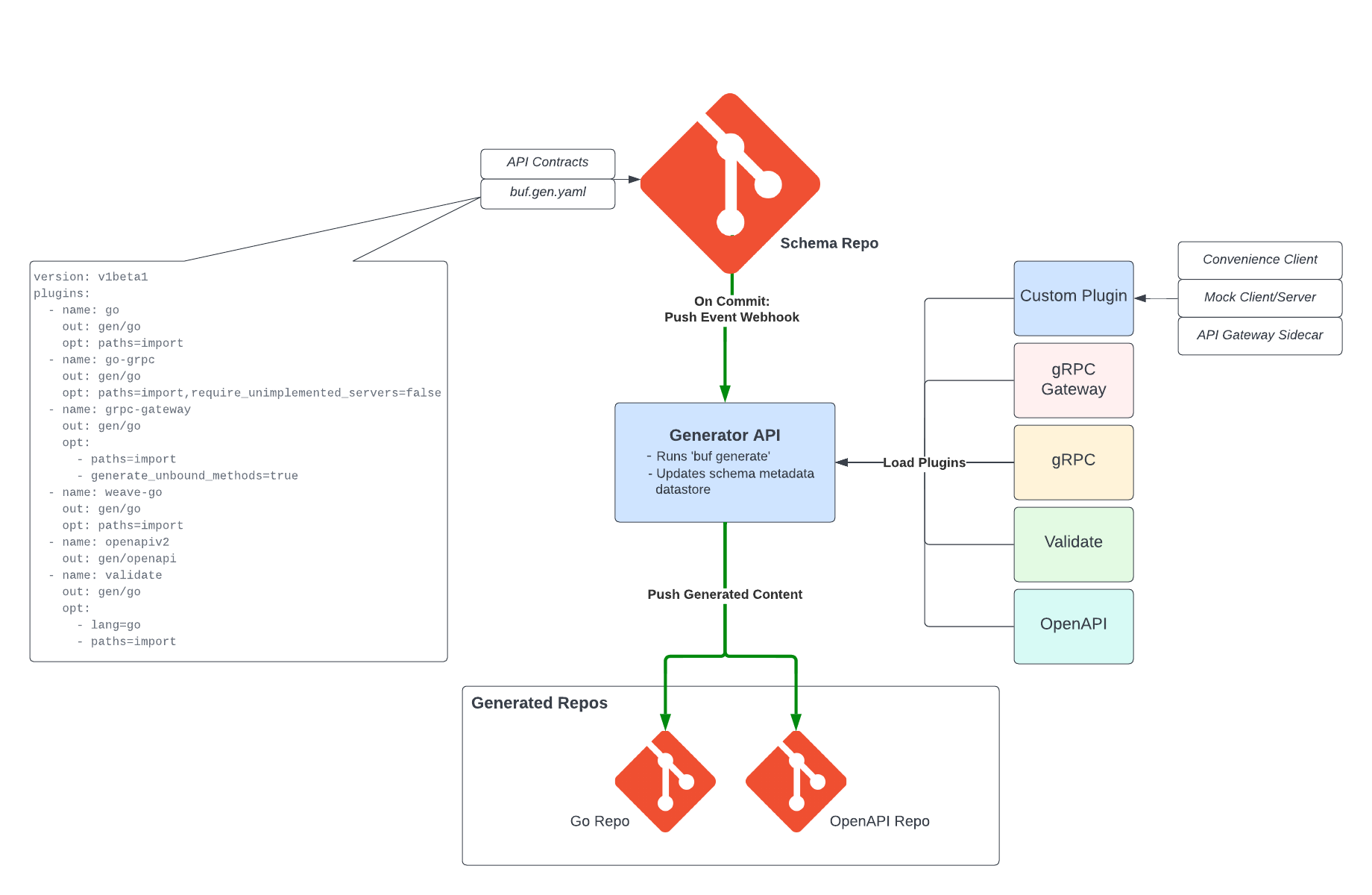
Proto Generation
The schema-generator-api maintains an up-to-date clone of the schema repo. When the service receives a webhook
from a push event to the schema repo, it simply runs buf generate. It uses
the buf.gen.yaml file, that is already cloned locally, to
generate content for all the included plugins in that file. A sample of the contents of the buf.gen.yaml file is shown
in the diagram above. This produces generated content for the following plugins:
protoc-gen-weave-go(built in-house)- protoc-gen-go
- protoc-gen-go-grpc
- protoc-gen-grpc-gateway
- protoc-gen-openapiv2
- protoc-gen-validate
We will dive into the magic of our custom in-house plugin
protoc-gen-weave-goin the wgateway section below.
A huge benefit of a generation api is that all generations are consistent. When each developer does generation themselves, you get a plethora of slight differences in their generated code if they don’t all have the exact right versions of the various plugins needed.
Updating Schema Metadata Datastore
We have a datastore that contains metadata for all “schemas” and all branches of the schema repository. This
is used to track things like:
- specific commit hashes that are used to build the API gateway sidecar container (more on this in the wgateway section)
- the full schema definition that is used in various tooling such as our developer CLI,
bart - generation pipeline statuses shown through
bart- this allows developers to run
bart schema pipelineto view the current status of a “schema” in the generation pipeline:
- this allows developers to run
Pushing Generated Content
Once buf generate has been run, the schema-generator-api service pushes the generated Go and OpenAPI content to two
separate generated repos. In the push to the generated Go repository, it also includes a metadata file that contains
the commit information included in the webhook event like: commit message, branch and commit sha.
Generated Repos
Generated OpenAPI Repository
Our repository that contains all generated OpenAPI specifications is used to serve an internal UI that shows a Swagger UI for each of our APIs. This is immensely useful for seeing what an API provides; especially, since this content is auto-generated and always up-to-date.
Generated Go Repository
Our repository that contains all generated Go code has quite a bit more in it than our generated OpenAPI repository.
Not only does it contain all the content that is generated from upstream protoc plugins such as: protoc-gen-go
and protoc-gen-grpc-gateway. But,
it also contains generated content from our custom plugin protoc-gen-weave-go such as: a generated client,
mock client/server, and all the code to initialize a new gRPC Gateway proxy (which is used by the gateway sidecar).
For example, the generated content for the feature-flags “v2” service looks like this:
schemas
└── feature-flags
└── v2
└── gateway
└── main.go # gateway sidecar
├── feature_flags.pb.client.go # custom client initializer
├── feature_flags.pb.client.mock.go # custom client mock
├── feature_flags.pb.client.mock_test.go # custom client mock tests
├── feature_flags.pb.go
├── feature_flags.pb.gw.go
├── feature_flags.pb.server.go # custom server initializer
├── feature_flags.pb.server.mock.go # custom server mock
├── feature_flags.pb.validate.go
├── feature_flags_grpc.pb.go
├── gateway.pb.go # custom gateway initializer
└── metadata.yaml # metadata with 'schema' repo commit information
Every single piece of that is autogenerated! 🤯
Let’s dig into the generated contents of our custom plugin protoc-gen-weave-go.
protoc-gen-weave-go and wgateway
Looking at the generated content above for the feature-flags/v2 API, we have the usual files generated from upstream
plugins such as:
protoc-gen-go -> feature_flags.pb.go
protoc-gen-go-grpc -> feature_flags_grpc.pb.go
protoc-gen-grpc-gateway -> feature_flags.pb.gw.go
protoc-gen-validate -> feature_flags.pb.validate.go
But, there are additional files that were generated from our custom protoc-gen-weave-go plugin:
- feature_flags.pb.client.go
- feature_flags.pb.client.mock.go
- feature_flags.pb.client.mock_test.go
- feature_flags.pb.server.go
- gateway.pb.go
Generated Client
Our custom plugin generates a convenience client for other services to use to talk directly to your gRPC service. This allows the service owner to declare what their default in-cluster address is through a custom option:
syntax = "proto3";
package featureflags.v2;
option (wv.schema.default_address) = "feature-flags.devx.svc.cluster.local.:9000";
By providing this custom option, we can use that in the generation of the convenience client. This is an example of what that auto-generated convenience client might look like:
// Code generated by protoc-gen-weave-go. DO NOT EDIT.
package featureflagspb
import (
...
)
const (
defaultAddress = "feature-flags.devx.svc.cluster.local.:9000"
)
// ConvenienceClient wraps the FeatureFlagsServiceAPIClient to allow method overloading
type ConvenienceClient struct {
FeatureFlagsServiceAPIClient
conn *grpc.ClientConn
}
// NewClient initializes a new ConvenienceClient for the FeatureFlagsServiceAPI gRPC service
func NewClient(ctx context.Context, addr string) (*ConvenienceClient, error) {
targetAddr := addr
if targetAddr == "" {
targetAddr = defaultAddress
}
// initialize gRPC connection to the 'targetAddr'
return &ConvenienceClient{NewFeatureFlagsServiceAPIClient(g), g}, nil
}
...
This is very useful because any service that wants to communicate to the feature-flags service can simply call
featureflagspb.NewClient(ctx, addr) to initialize a client to talk directly to that service. And the addr argument
is typically an empty string and only explicitly set for local development when there is either a port-forward or
service running locally.
Generated Server
There isn’t anything particularly special about the generated server other than the fact that the NewServer function
is auto-generated with all the required interceptors and logic to spin up a new feature-flags gRPC server.
Generated Gateway
The generated gateway files are the special sauce that makes our API gateway work. The gateway.pb.go file contains all the
functionality necessary to spin up a new gateway that will serve as the HTTP->gRPC proxy for requests coming from the edge.
This generated file supports running the gateway in two ways: manually in the service code or automatically with a
sidecar container.
The generated gateway code looks something like this:
// Code generated by protoc-gen-weave-go. DO NOT EDIT.
package featureflagspb
import (
...
)
// Gateway is a personalize gateway for the FeatureFlagsServiceAPI schema
type Gateway struct {
*wgateway.Gateway
}
// NewGateway returns an initialized Gateway with the provided options for the FeatureFlagsServiceAPI schema
func NewGateway(ctx context.Context, opts ...wgateway.GatewayOption) (*Gateway, error) {
gateway, err := wgateway.New(ctx, options(opts)...)
if err != nil {
return nil, err
}
registerRoutes(gateway)
return &Gateway{gateway}, nil
}
// Run executes the gateway server for the FeatureFlagsServiceAPI schema
func (g *Gateway) Run(ctx context.Context) error {
// initialize a new connection 'conn' with various interceptors
// this is done with grpc.DialContext
err = RegisterFeatureFlagsServiceAPIHandler(ctx, g.RuntimeMux(), conn)
if err != nil {
return werror.Wrap(err, "failed to register grpc gateway handler")
}
return g.ListenAndServe()
}
...
func registerRoutes(gateway *wgateway.Gateway) {
gateway.RegisterRoute(http.MethodPost, "/feature-flags/v1/flags")
gateway.RegisterRoute(http.MethodDelete, "/feature-flags/v1/flags/{id}")
...
}
protoc-gen-weave-go extracts the grpc-gateway annotations and fills in the registerRoutes function to register
all routes with the gateway. 😮
So, if the service owners choose to run the gateway manually in the service code, it’s as easy as:
gateway, err := featureflagspb.NewGateway(ctx)
if err != nil {
// handle error
}
err = gateway.Run(ctx)
if err != nil {
// handle error
}
While this is not the majority, there are still use-cases for running the gateway manually in the service code such as:
- Custom authentication
- Adding additional handlers to serve files (because serving files in gRPC is 💩)
Interestingly, the gateway sidecar runs the exact same code that is used when running directly in the service. The
difference is that it is attached to the Kubernetes Pod as an additional container and the service owner doesn’t have to
worry about manual execution. The code that is compiled into the sidecar container is located in the gateway directory
of our generated Go repo:
schemas
└── feature-flags
└── v2
└── gateway
└── main.go # gateway sidecar
This file is roughly 25 lines long and contains, more or less, the same exact code that is required when running manually:
// Code generated by protoc-gen-weave-go. DO NOT EDIT.
package main
import (
...
pb "weavelab.xyz/schema-gen-go/schemas/feature-flags/v2"
)
func main() {
...
gateway, err := pb.NewGateway(ctx)
if err != nil {
// handle error
}
err = gateway.Run(ctx)
if err != nil {
// handle error
}
}
Running Locally
Being able to run your service locally is a must. If the gateway code is executed alongside the service code, running the service locally is as easy as just running the service. But, if the gateway code is attached at deploy-time as a sidecar container, the service’s local development configuration file must specify the specific gateway sidecar to run.
# local development configuration
run:
withSidecars:
- apiGateway:
schema: feature-flags/v2
...
Either way, the gateway code gets executed. This allows our engineers to verify that their routing maps correctly, or their custom gateway enhancements get processed properly.
Generating Sidecar Containers
Ok, so I mentioned above, that when our generator service commits all the content to the generated Go repository, it
also includes a metadata file that contains the commit message, branch and commit sha. This is where that comes into play.
Whenever there is a commit to the generated Go repository, a GitHub Action workflow runs that determines if a change was
made to any schemas. For any schemas that changed, and as long as those changes were accompanied by that same metadata
file, the GitHub Action generates a gateway sidecar container by compiling the above .../gateway/main.go file, and
then pushes it up to our container registry.
This metadata file is also used at deploy time to attach the correct gateway sidecar container version to the deployment that is in flight.
Schema Docs UI
Another great benefit of having two repositories with all generated content for all APIs in our system is that we can build a UI that serves both the GoDocs and Swagger UI for all schemas. So, we built a service that watches both of those generated repos for changes, and updates its local cache so the documentation that is served in the UI is always up-to-date.
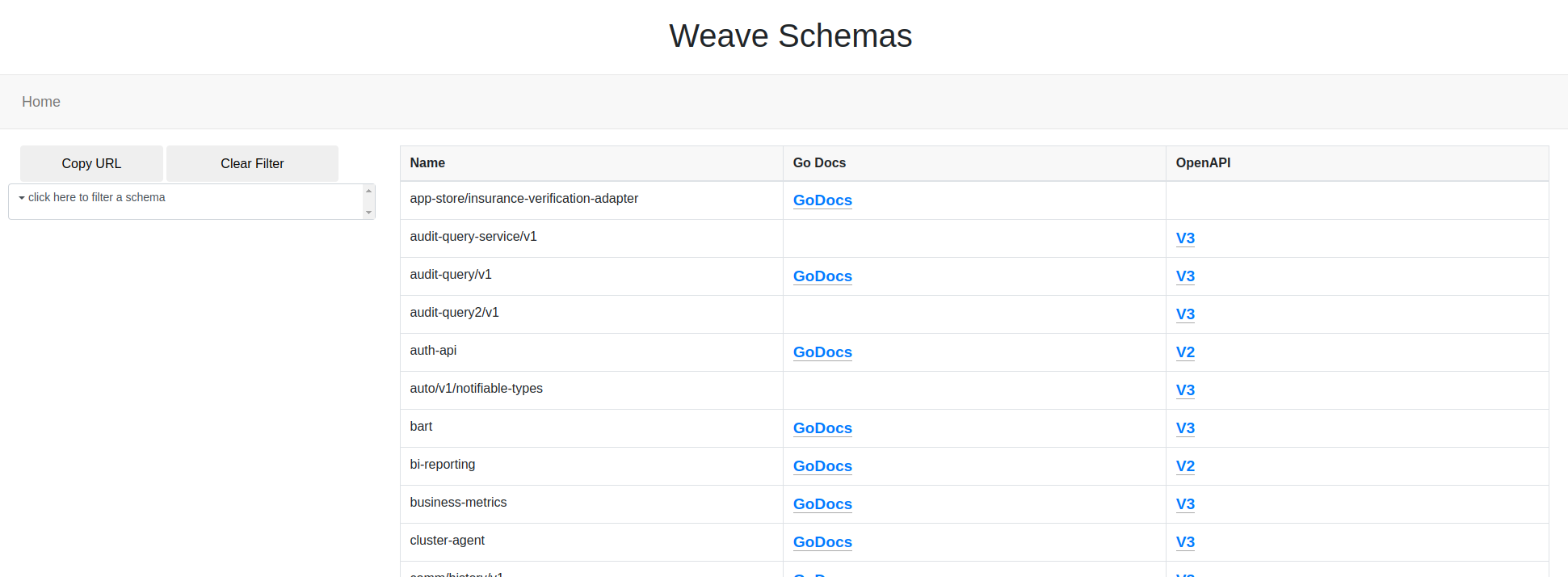
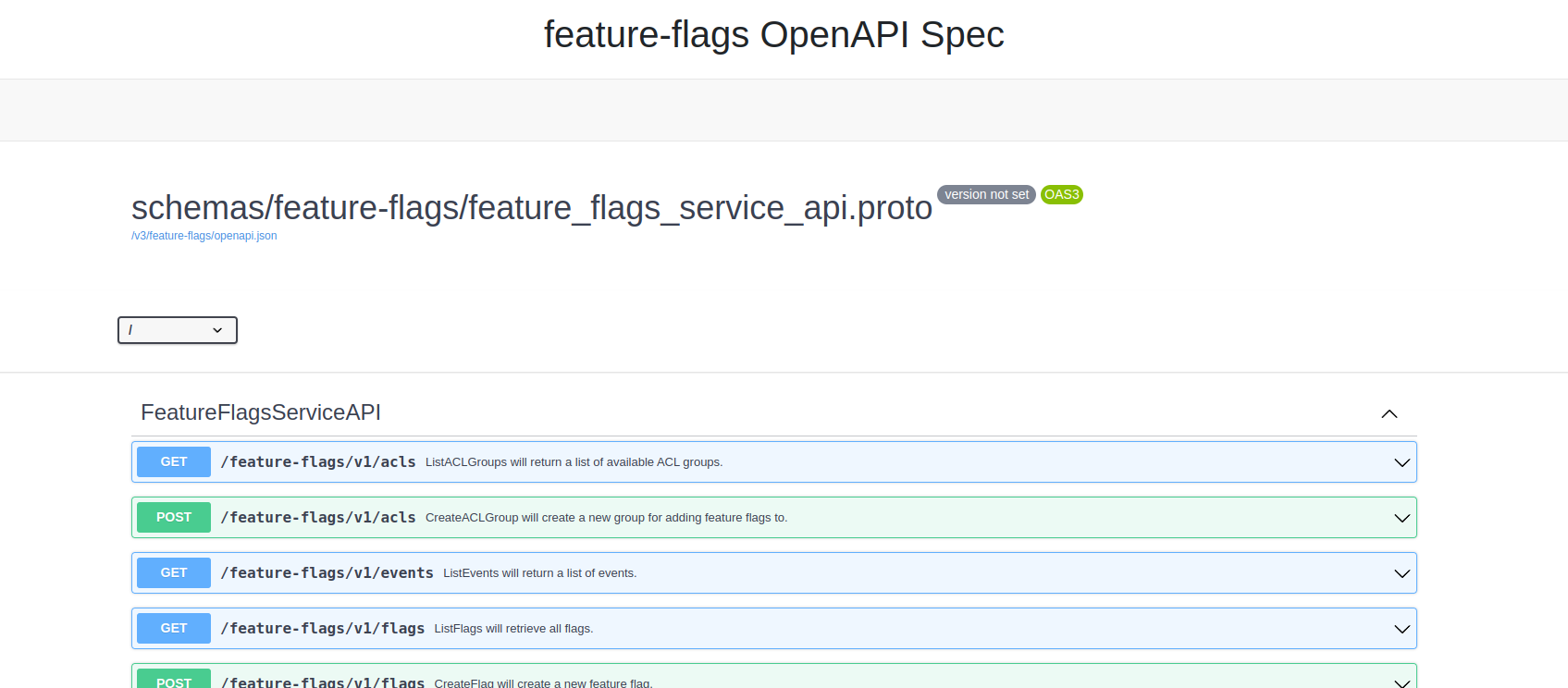
As you would expect, clicking the “V3” OpenAPI spec shows something like this:
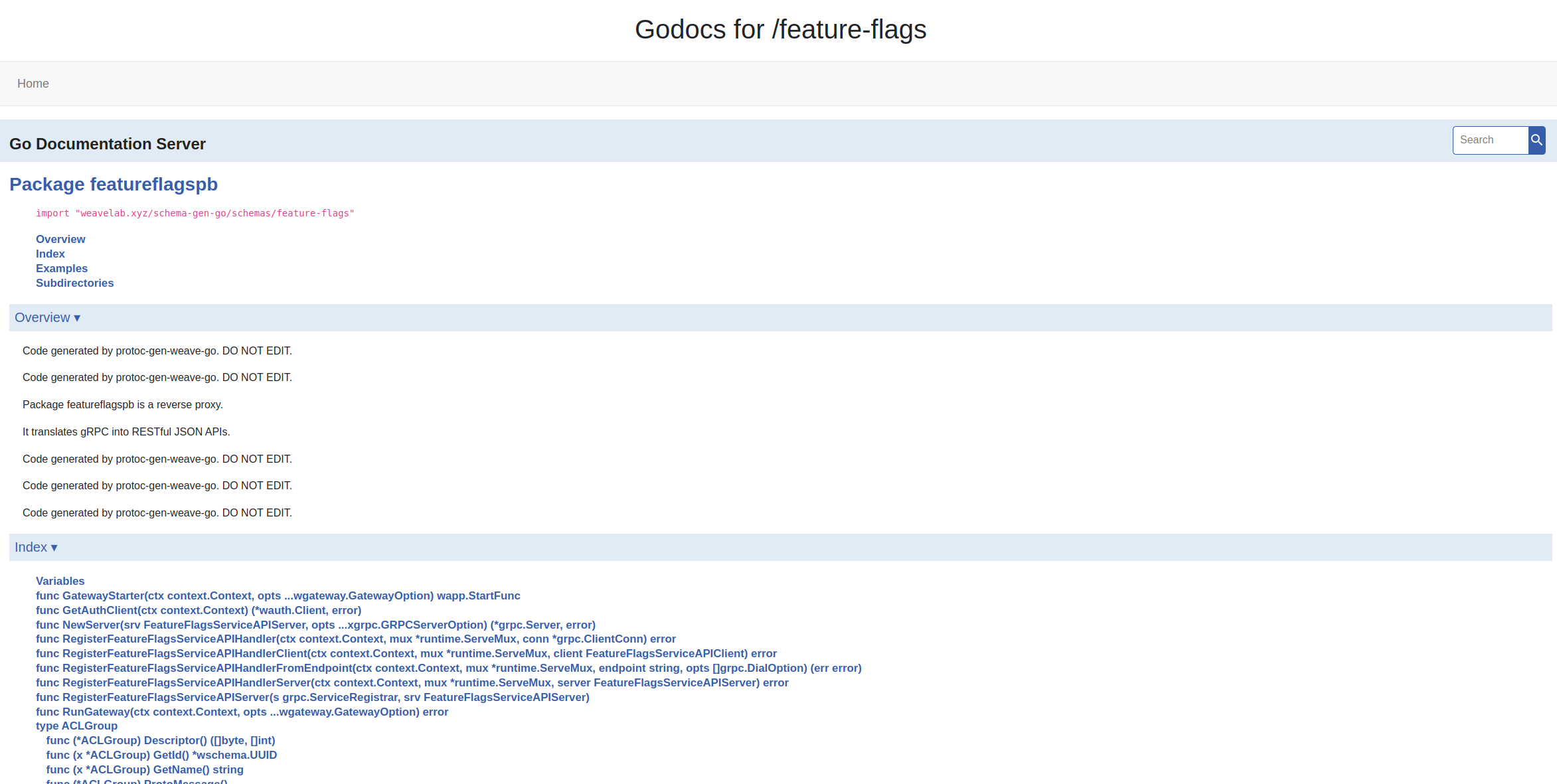
And clicking the “GoDocs” link shows something like this:
This has been immensely beneficial. We now have a fully-automated UI of documentation for every schema, or API, in our system.
Conclusion
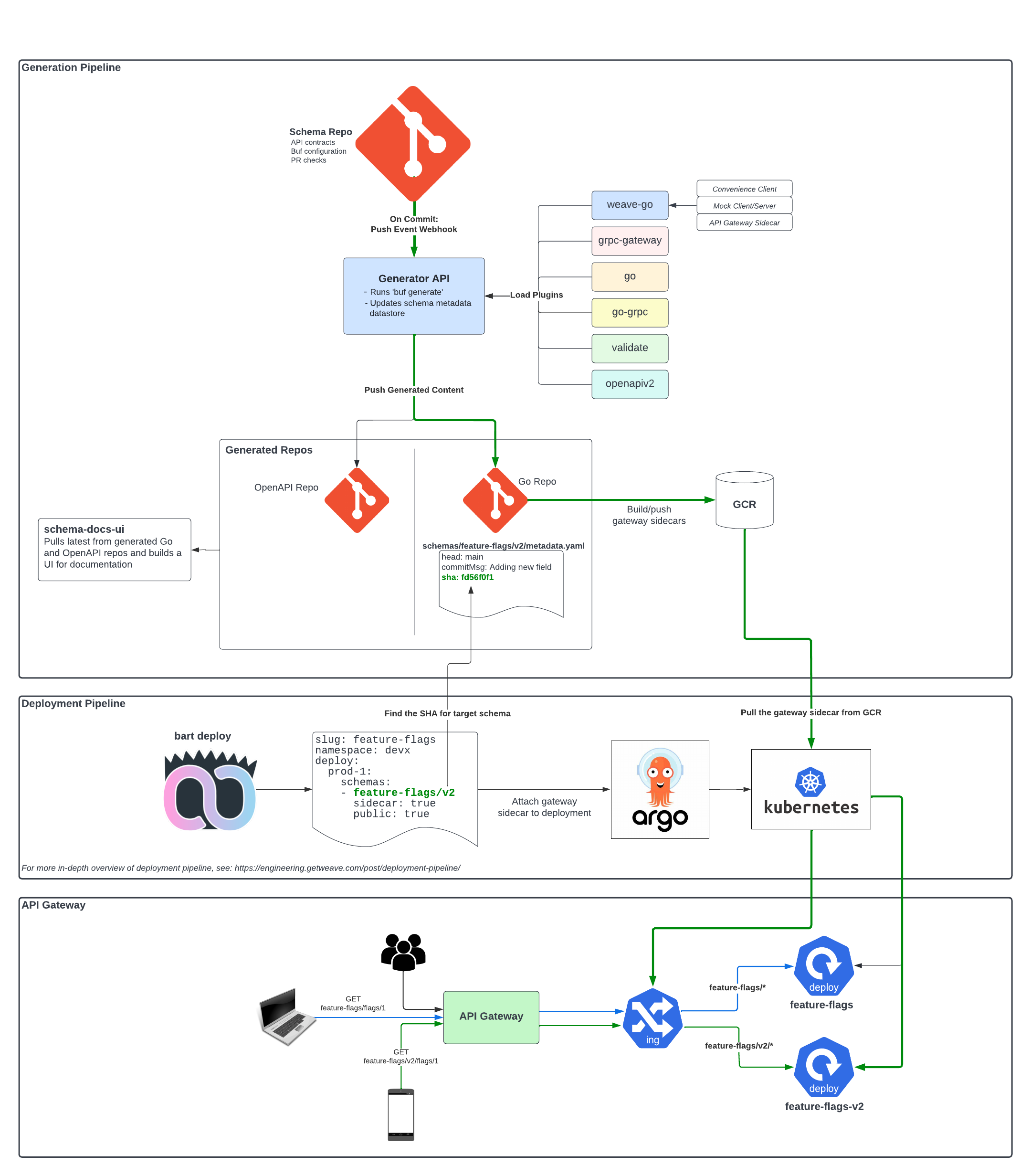
We have gone over how our protos, or APIs, are developed and generated. This is an overall look at the system we have built and how it fits into our deployment pipeline:
Here at Weave, we are dedicated to challenging the status quo. Because of this, we typically come up with unique solutions to take load off our developers and help them bring value to the customer more efficiently. Now that you have read this, we hope you are also excited to start challenging the norm and start building systems that challenge the norm. There is always (ok, most of the time) a second and third option when facing a technical challenge. You just have to think outside the box and put pen to paper.