Deployment Pipeline
At Weave, we deploy things. We deploy all the things. And we do it all through GitOps.
The typical workflow of a Weave developer would look something like this:
- Checkout feature branch
- Write code
- Run/test the service locally
- Push code to GitHub (this builds a container)
- Run
bart deployto deploy container to cluster
Looking at this workflow, you can see that the only thing a developer needs to use besides GitHub, is bart.
bart is our CLI tool, built by the DevX team, that allows developers to perform all their day-to-day tasks including:
- Deploying services
- Running services locally
- Managing secrets for services
- Viewing build results
- Inspecting live deployment state
- etc…
bart will be its own post at some point. It is the mechanism that developers use to manually deploy services to
our various clusters. It is one of the starting points in the diagram below 👇
Overview
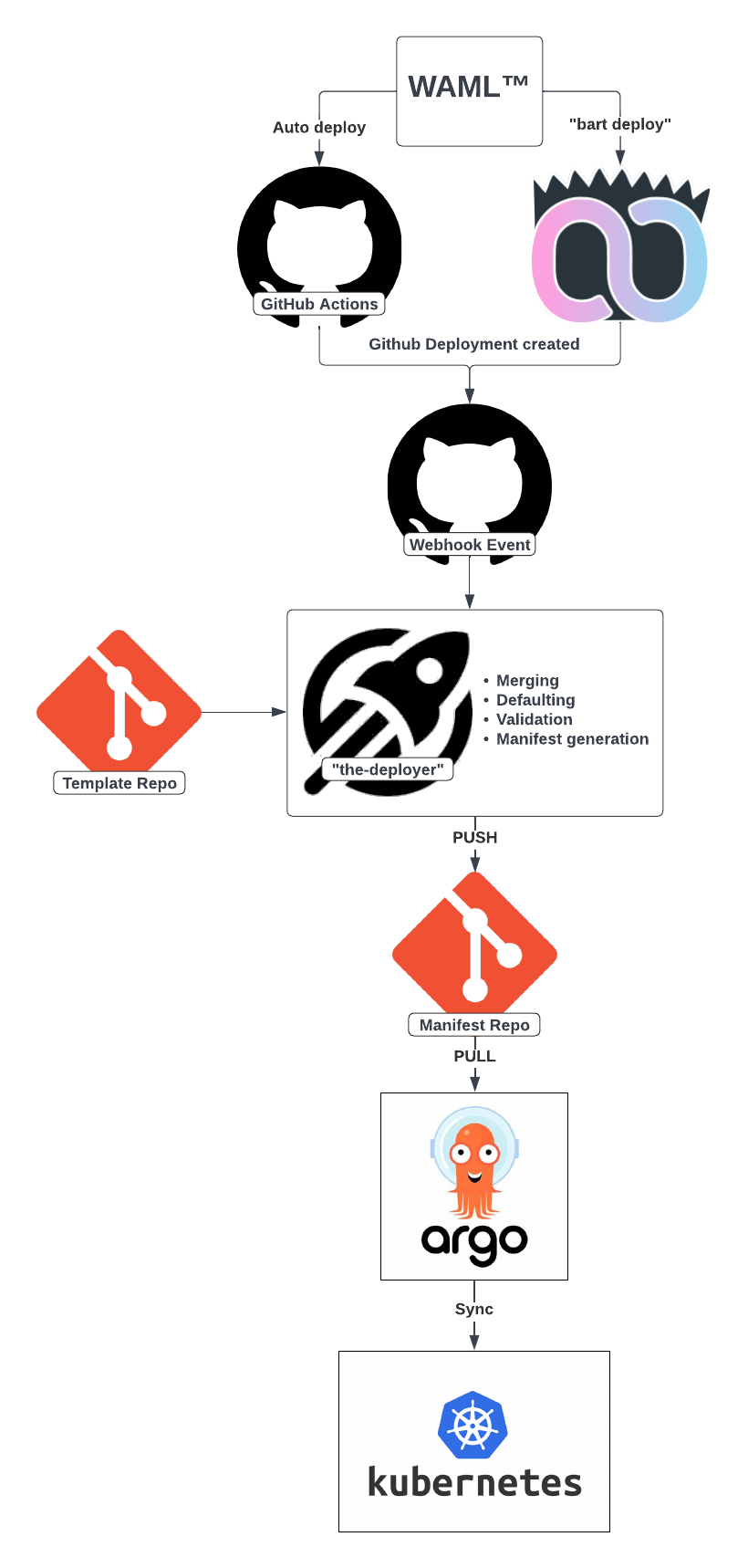
At Weave, we process between 300-400 deployments per day and our entire deployment pipeline is Git-based. All of our Kubernetes manifest templates live in a Git repository as well as the default values for each template. Our rendered Kubernetes resources also live within a single repository that is namespaced by each of our different clusters running in Google Cloud Platform (GCP). When the main branch of that repository changes, a webhook event is sent to our ArgoCD installations that run within each cluster. If the state of the target cluster has changed, Argo pulls the latest state of the manifest repository and syncs it to Kubernetes running within the same cluster.
The starting point for every deployment is a valid WAML. The WAML™, or .weave.yaml lives at the root of every
service’s repository. For each service, it defines:
- The name
- The team that owns it
- How to deploy it
- How to alert for it
- etc…
The WAML is the one true way that Weave developers interact with systems such as Kubernetes, Prometheus, AlertManager, etc. and a valid WAML is required for every deployment.
Let’s dive a little deeper into the diagram above.
Example Deployment Workflow
Take the following simple WAML:
schema: "2"
name: My App
slug: my-app
owner: devx-team-fake-email@getweave.com
slack: "#squad-devx"
namespace: devx
defaults: # define de-duped sections of deploy metadata that can apply to any "deploy" target
- match: "*" # glob pattern match of any "deploy" target
service:
- ports:
- name: http
number: 8000
ingress:
- hostPrefix: my-app # subdomain of cluster's main host
public: true
paths:
- path: /
servicePort: 8000
deploy:
prod-cluster-1: # cluster
env:
- name: MY_ENV_NAME
value: some-value
slo:
requestClass: critical # a predefined slo class for 99.99% availability
autoscaling:
horizontal:
minReplicas: 3
maxReplicas: 10
cpu:
averageUtilization: 75
First Step: Create Deployment
Once a developer finishes their work on a particular service, they push their changes to Git. This runs a
GitHub Actions workflow that lints, tests, and builds a container. Running bart builds will print out the most recent
build containers for a specific repository, or service.

Once a build “TAG” is obtained, a simple bart deploy <TAG> <cluster>is all that is needed to manually deploy
the above WAML to the specified cluster. In the example WAML above, and with the most recent container image “TAG”
from above, this command would be bart deploy 1.0.202206151506-sha.649008fb prod-cluster-1.
To help with automating deployments, we also have a workflow step that can be included in any repository’s GitHub Actions workflow file that will auto-deploy to specified cluster(s). Many teams have implemented this custom step to auto-deploy on merges into the main branch.
- name: Deploy
if: github.ref == 'refs/heads/main'
uses: ./actions/deploy/
It is important to note that only thing that happens in both manually deploying with bart and automatically deploying with GitHub
Actions, is that a GitHub Deployment resource is created through the GitHub API.
Second step: the-deployer
Once a GitHub Deployment has been created, the-deployer receives a webhook event from GitHub. Then, the-deployer must perform:
merging, defaulting, validation, and manifest generation.
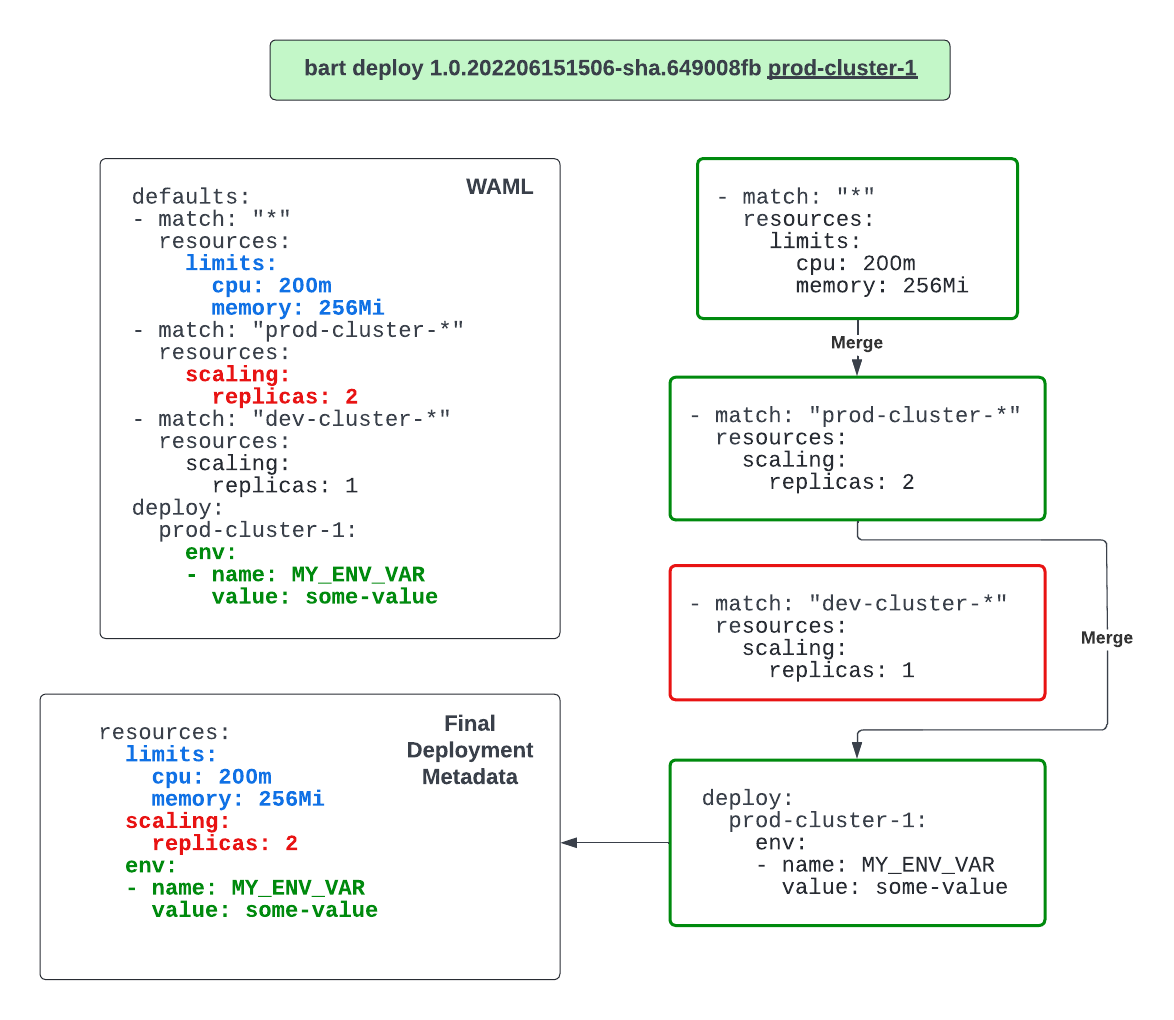
Merging
The first thing the-deployer does is merge together any and all deployment metadata sections into one set of metadata for the
deployment to use. Let me explain…
The WAML allows for declaring sections of metadata that deployments to specific clusters can use. Looking at the sample WAML above, you
can see a defaults section that outlines a set of default metadata:
defaults: # define de-duped sections of deploy metadata that can apply to any "deploy" target
- match: "*" # glob pattern match of any "deploy" target
service:
- ports:
- name: http
number: 8000
ingress:
- hostPrefix: my-app # subdomain of cluster's main host
public: true
paths:
- path: /
servicePort: 8000
These defaults sections can apply to any of the deploy targets, or clusters, defined in the WAML. In our example
deploy command, bart deploy 1.0.202206151506-sha.649008fb prod-cluster-1, the deploy target is “prod-cluster-1”.
The glob match pattern from the defaults section above is marked as match: "*". This means that, its set of
deployment metadata will apply to all deploy targets, including “prod-cluster-1” from our sample deploy command.
In this merging process, the first step is to take any of these defaults sections of metadata that have a glob
pattern that matches the target deploy (ie. “prod-cluster-1”) and merge them together. We do this by iterating
through any matching defaults sections, in order, and applying them on top of each other. The last thing that
happens is to apply the metadata from the target deploy section so that it comes last and takes precedence.
This process is shown below:
Defaulting
Once the deployment metadata is all merged together into one set, the-deployer needs to fill in all default values.
These are maintained in our templates repository. Our templates repository contains all our Go templates that specify
all the resources that must be rendered for each of our defined templates. Most services use the same “backend-default”
template, but some, like our frontend services or cronjobs, must provide a “template” field in the WAML to let
the-deployer know it should use the resources from a different template. Each template is accompanied by a
defaults.yaml file that defines all the default values that should be applied if no overrides are given in the WAML.
the-deployer maintains an up-to-date cache of these template resources and their default values in memory so that whenever deployment events are
received, it has the latest version.
The templates repository structure looks like this:
templates repo
└── apps # templates
├── backend-default
└── defaults.yaml
latest
├── deployment.yaml.tmpl
├── service.yaml.tmpl
└── etc...
├── frontend-default
├── cronjob-default
└── etc...
The defaults.yaml file roughly looks something like this:
service:
port: 8000
ingress:
port: 8000
resources:
requests:
cpu: 200m
memory: 256Mi
limits:
cpu: 400m
memory: 512Mi
scaling:
replicas: 3
maxUnavailable: 0
maxSurge: 2
This file, for example, tells the-deployer that if there is an ingress present, and no port number has been given,
that it should use the default port of 8000. Virtually, every single aspect of the WAML has a section in these
defaults.yaml files. This gives developers smart defaults to eliminate toil and minimize overly verbose configs,
while still allowing them to customize every single part of a deployment.
Validation
After everything has been merged and all defaults have been applied, the data is then validated. We have 14 different validators that run for every single deployment. These validators include things like ensuring:
- ports are mapped correctly from ingress to service to pod
- referenced secrets actually exist
- an ingress doesn’t already exist with the same host
- feature branches aren’t being deployed to production
- etc…
In the event that validation does not pass, the deployment is marked as a failure in GitHub and a Slack message is sent to the team and developer who initiated the deployment.
Manifest Generation
If a deployment passes validation, the-deployer generates all the K8s resources necessary, based on the template that
is provided in the WAML, and then pushes them to our manifest repository. Our manifest repository contains all
resources, for all clusters, that are namespaced according to each cluster. The directory structure looks something
like this:
manifest repo
└── manifests
├── cluster-1
└── cluster-2
` └── <namespace>
└── <app-name>
├── <2nd to last deploy id> # we keep a 5 revision history of deployment resources
├── <last deploy id>
└── latest # this is the directory that Argo syncs from
├── deployment.yaml
├── service.yaml
└── etc...
We keep a 5 revision history of deployment resources for all services. This allows us to perform rollbacks of a
service via bart rollback by simply copying over the contents of a previous deployment’s directory into the “latest”
directory, which is the directory that Argo syncs from. This guarantees that when we rollback an application, it is
being rolled back to the exact state it was in when that version was live.
In the event that our example deployed WAML passed validation and was deployed, the following resources would be generated and pushed to the manifest repository:
- K8s deployment with 3 replicas
- K8s service and service account
- Traefik ingress routes
- Cached cert(s) for ingress using cached-certificate-operator
- Vault roles/policies
- Default Prometheus alerts for:
- CPU throttled
- Container restarts
- Container waiting
- Memory usage reaching limit
- Max replicas reached
- Others for gRPC, Database, and Redis
- SLO recording rules and alerts for 99.99% availability
- Horizontal pod autoscaling (HPA) config
- IAM service account
If the-deployer succeeds in pushing this generated content, it marks the deployment as a success in GitHub and moves
on to the next one.
ArgoCD -> Kubernetes
Once all the resources have been pushed to our manifest repository, a webhook event is sent from GitHub to our ArgoCD installations in each one of our clusters. This triggers the sync from Argo to Kubernetes.
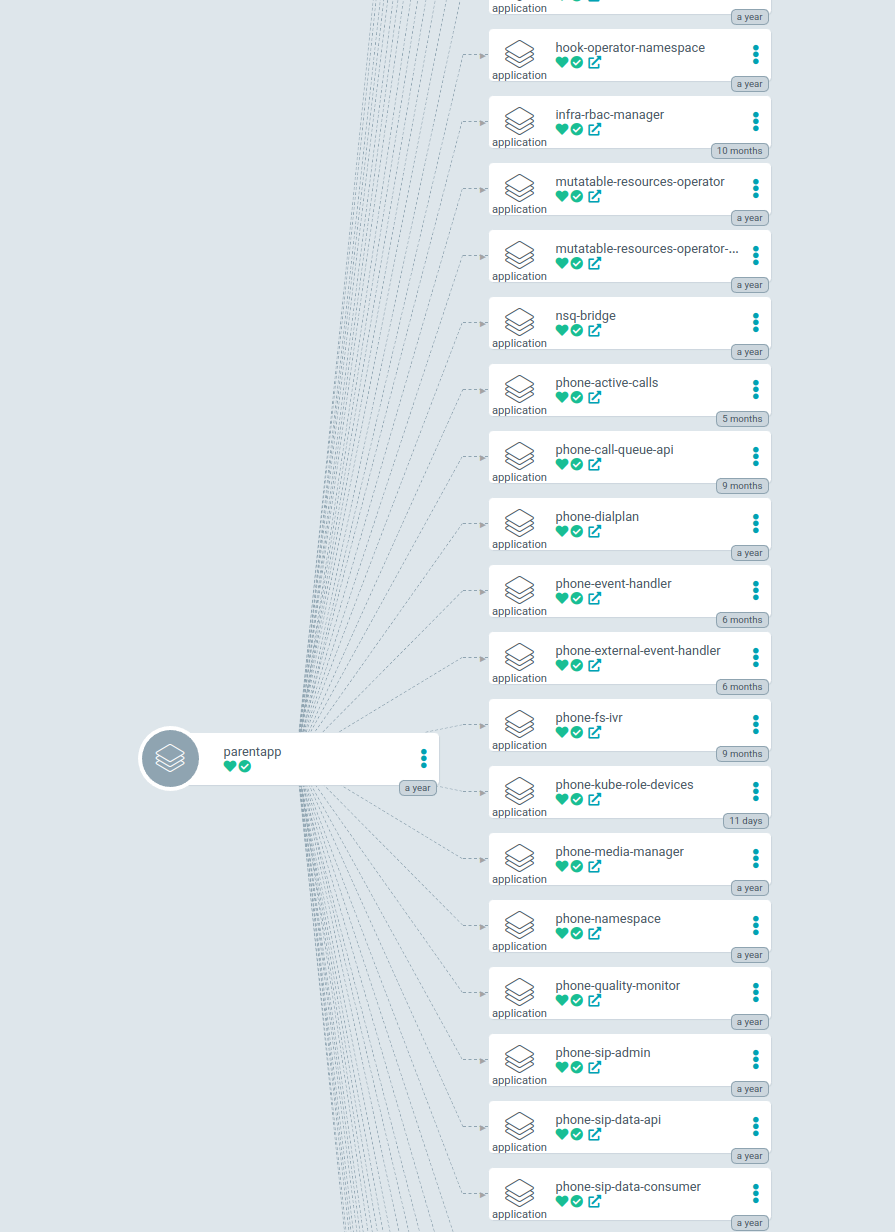
App of Apps
At Weave, we follow the “app of apps” pattern, which means that each one of our clusters has a “parent app” created. This “parent app” points to a directory within the manifest repository that contains all the applications that should be running in the cluster. This means that we are able to rebuild the state of that cluster automatically from scratch! Since we have over 500 microservices running in our main production cluster, this is very powerful.
This view in Argo looks like this with all microservices stemming off of the main cluster “parent app”:
Argo Application
A huge benefit of ArgoCD is that they expose a CRD (custom resource definition) called an ArgoApplication. This allows
you to create an ArgoApplication for each application you have running in your cluster that serves as the parent
application of all the resources tied to that application. This includes your typical Kubernetes resources such as a
deployment, service, ingress, etc. But, this can also include any CRD your application needs such as a Redis instance,
CloudSQL database, or GCP IAM policies. This provides a single pane view of everything about your application.
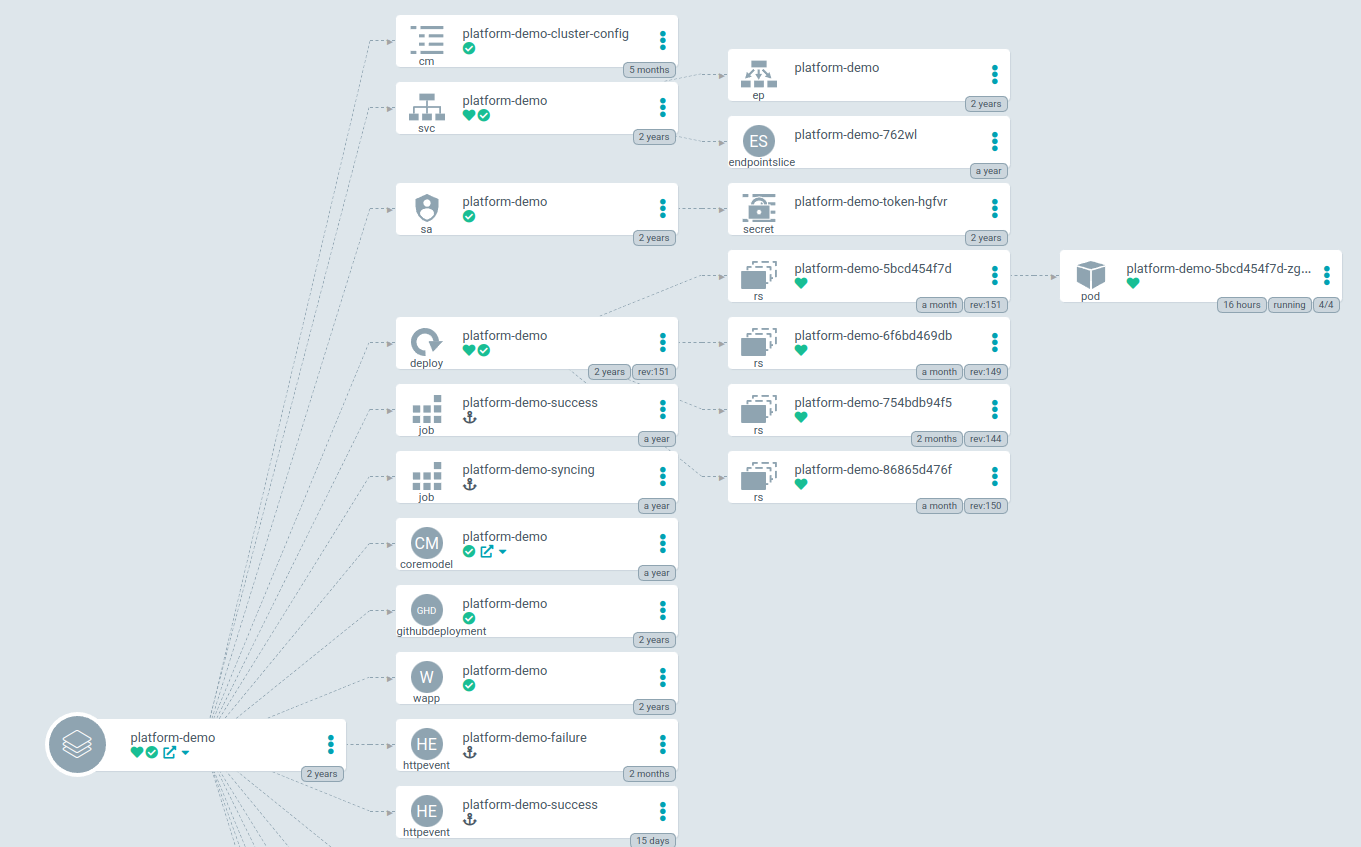
You can even add links directly to your Argo Application!
Conclusion
The beauty of all of this is that it is 100% Git-based. All our K8s resource templates live in Git. All of our default template values live in Git. Argo syncs all of these resources from Git. And the only thing our developers have to think about is pushing to Git.
Because we control our entire deployment pipeline, we have metrics that allow us to measure our success. As I am writing this, here are the metrics for the last 6 hours of our completely Git-based deployment pipeline:
| Metric | Duration | Description |
|---|---|---|
| Average Deployer Time | 4.6s | How long it takes the-deployer to merge, default, validate, generate manifests, and push to the manifest repo |
| Average Argo Pickup Time | 19.4s | Average time between a developer running bart deploy and Argo receiving the webhook from GitHub to start the sync process |
| Average Developer Wait Time | 24.03s | Average time between a developer running bart deploy and visibly seeing Argo syncing their deployment |
| Average Argo Pickup to Synced Time | 31.24s | Average time between Argo receiving the GitHub webhook to a deployment fully synced and applied to Kubernetes |
| Average Total Deploy Time | 55.24s | Average time a deploy takes from start to finish (bart deploy => resources synced in Kubernetes) |
We are very proud of the work we have done to get our full deployment process under a minute. But, at Weave, we are never satisfied. We are continually striving for faster and more efficient deployments. And that’s exactly what we will do. 🙂